 Laravel Development
Laravel Development React Development
React Development Vue.js Development
Vue.js Development Angular Development
Angular Development Python Development
Python Development Flutter Development
Flutter Development iOS/Swift Development
iOS/Swift Development DigitalOcean Development
DigitalOcean Development AWS Development
AWS Development Azure Development
Azure Development ConnectShip Services
ConnectShip ServicesHow google works!
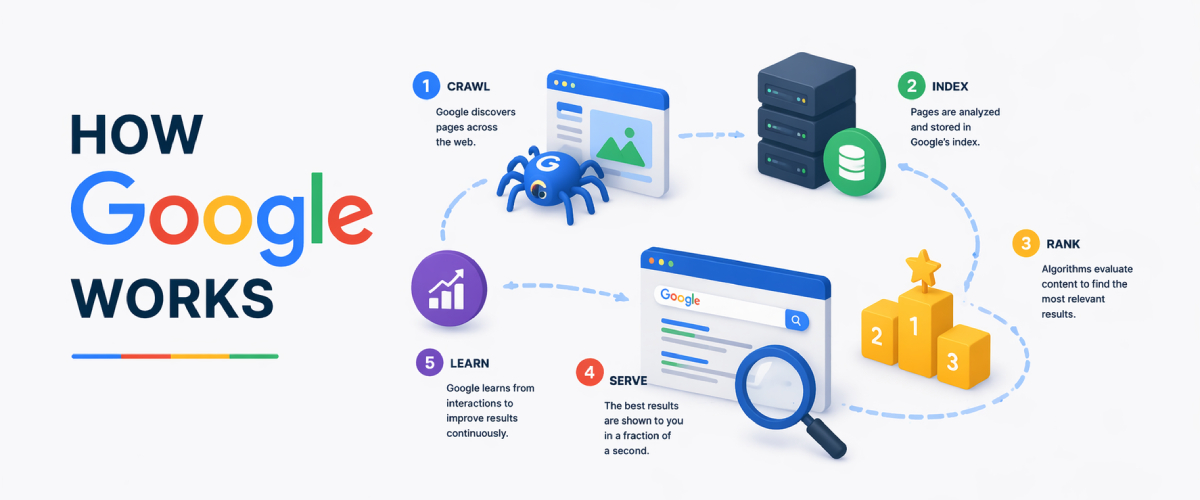
Understanding How Googlebot Works and SEO Insights
This blog is majorly inspired by the SMX West 2016 Keynote speaker Paul Haahr- @haahr, Rank Engineer at Google. I am writing this blog because I think if a digital marketer wants to make the best of any SEO strategy in this world, he/she ought to know how things actually work on the other side of the world more clearly - I am talking about the search engine’s side- Google’s side.
Google uses a self-developed software called ‘Googlebot’ which collects documents from all over the web or at least most of the web to create indices that render Google’s Search Engine Results Page (SERPs) to the search engine user. A Search Engine Results Page is the page displayed as a result of the searcher’s query.
How Googlebot Crawls the Web
When a query is submitted into Google’s search engine, these Googlebots, which are also called ‘spiders’, begin crawling into a random set of seed websites or webpages extracting outgoing links from them. The spiders then follow these links landing onto a whole different set of websites extracting outgoing links from them. This is how Googlebots gather documents and use these links to understand the structure of the web and find relevant pages.
After the spiders have crawled enough of the web and the majority of its content, they build a specific index or what Google calls ‘Keyword Inverted Index’, collecting and storing all the pages with keywords/phrases relevant to what the user types in on Google’s search engine as the query. Once the index is created, the bots calculate which pages out of all the documents are the most relevant to the user’s query. Along with this they also check which pages are the most popular, reliable, trustworthy, and other factors (signals). All these metrics are a part of Google’s PageRank Algorithm. To understand PageRank Algorithm, please read our blog What Google Humms..these days..
Semantic Search Engine
Basically, Google up until a few years back would only analyze the crawled pages by extracting links and few other things like rendering content but its core job would be to extract outgoing links from webpages. However, since a few years, Google has added/improved on how crawlers analyze web pages and build indices based on its analysis. The added functionality is called ‘semantic search engine’. What semantic search engine does is that it increases the accuracy of relevant search results by understanding the meaning of the query in context of the searcher’s intention or actual need.
Building a ‘web index’ according to Google is just like building a book index. Web Index is, in short, for every word a list of pages that the word appears on. Keeping in mind that the scale of the web is too large, Google breaks the web into groups of millions of pages and each group is called an ‘index shard’. This way the web is divided into thousands of index shards which makes up a substantial part of Google’s Index Building Process.
Handling Queries
What does Google do after it gets a query? It understands the query first—part of the semantic search if you will. It asks several questions such as “Does the query name know any entities? Are there any useful synonyms? In what context should the user input be treated?”. After understanding what the user is actually looking for, Google sends the query to all the ‘shards’. The index shard then finds matching pages, scores them (what is called ‘PageRanking’) and conclusively sends the top pages sorted by score. The returned pages are then tested for ‘signals’ like spam, duplication, clustering site links, demoting or promoting sites on its base.
Types of Signals
- Query Independent: includes PageRank, language, Mobile-friendliness
- Query Dependent: includes features of page and query, Keywords hints, Synonyms, Proximity
How Google Positions Pages
Google uses something called Reciprocal Ranked Weightage wherein each site from the SERP is given weightage beginning from the very first.
- Site 1 - has a weightage of 1
- Site 2 - has a weightage of ½
- Site 3 - has a weightage of ⅓
- Site 4 - has a weightage of ¼
Google is known to conduct ‘Live Experiments’ all the time. Paul Haahr says it is very rare that a site is not involved in a ‘Live Experiment’ at any given point of time. Google also employs what it calls a ‘Needs Met Rating’. The rating scales from ‘Fully Meets’ to ‘Fails to Meet’ including in between them ‘Very Highly Meets’, ‘Highly Meets’, ‘Moderately Meets’, ‘Slightly Meets’.
Needs Met Rating
- Fully Meets - The need is ‘fully met’ when a user types in, for example, ‘wwe’ (World Wrestling Entertainment) and Google returns with the search result ‘www.wwe.com’. Basically it means the query that results in absolutely unambiguous page return.
- Very Highly Meets - A query that could possibly result in a few web pages or websites.
- Highly Meets - A query that results into a highly informative, authoritative page such as Wikipedia.
- More Highly Meets - Depending on the location of the user, Google gives different results. For example, a person in Kashmir (India) types ‘apples’, the user is likely returned pages about the fruit. In California, typing ‘apple’ returns pages about the tech company Apple.
- Moderately Meets - Several useful informative links.
- Slightly Meets - A query results in a less than the most useful informative page which could be acceptable but not great, ambiguous but relevant.
- Fails to Meet - A search result that is completely ambiguous and not relevant or useful to the user at all.
Page Quality Concepts by Google
- Expertise
- Authoritativeness
- Trustworthiness
Webpages/sites that deal with subjects like medical care are expected to rank high on trustworthiness due to the possible impact of their information on users. This is how Google classifies ‘Low Quality Pages’:
- The quality of the main content is low
- There is not enough/unsatisfying amount of content on the main page
- The author does not have expertise or is not trustworthy or authoritative on the topic
- The website has negative reputation
- The secondary content is distracting or unhelpful